

Almost four years since the release of ChatGPT, every firm has an AI strategy. Far fewer have a deliberate data strategy. The gap between AI strategy and data strategy will define which firms lead the next decade of transactional practice.
When every firm has access to the same foundation models and tools that leverage them, technology adoption alone is no longer a differentiator. What sets firms apart from peers is proprietary data: the firm’s unique market expertise, distilled into structured, queryable, and centralized knowledge assets.
A deliberate data strategy unlocks a firm’s competitive advantage by turning deal documents and other forms of institutional knowledge into a compounding intelligence layer, making each new matter an asset for winning the next mandate, negotiating from a position of authority, and enabling the highest levels of strategic guidance to clients.
Knowledge isn’t an advantage unless it scales
The absence of a deliberate data strategy is itself a strategy, albeit an increasingly risky one. Firms that fail to invest in institutional knowledge capture are betting on the adequacy of the status quo: Associates relying on hallway conversations and firmwide emails to find precedent. A practice group maintaining a spreadsheet of key terms. Critical context about a negotiated term living in the heads of partners who worked on the deal.
This was the default strategy for decades. Today, it’s untenable. Firms who accept the status quo cede ground to peers who come to the next pitch or negotiation armed with the full scale of their firm’s competitive intelligence.
The firms pulling ahead in the deal intelligence race treat unstructured data as a problem worth solving with the same rigor they bring to all of their work. A deliberate data strategy is how institutional knowledge becomes institutional advantage.
A four-level framework for data maturity
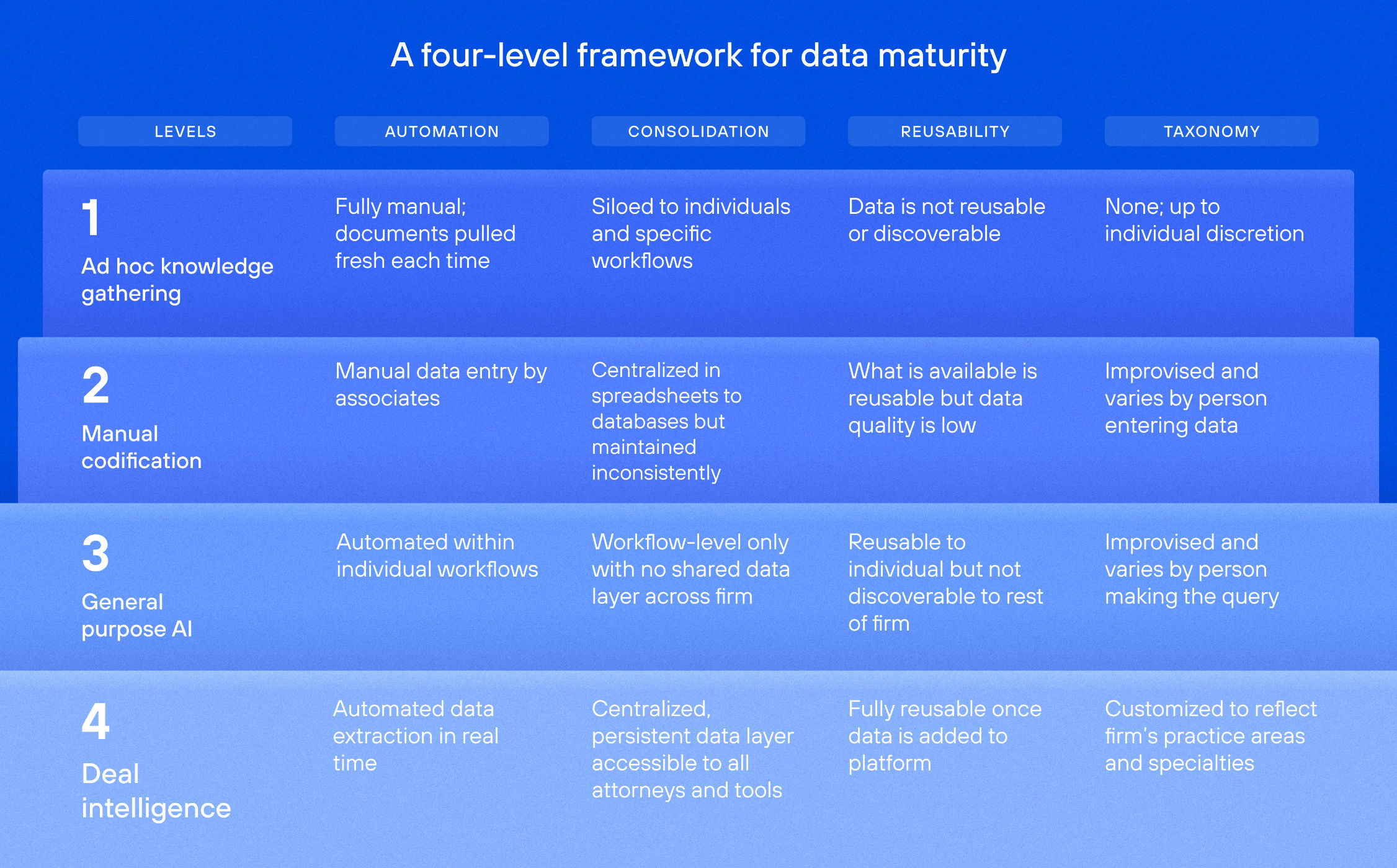
We use this framework to classify the maturity of a firm’s data strategy. Moving up the curve, firms shift along four axes: manual to automated, workflow-based to system of record, one-time analysis to reusable data, and generic structures to taxonomies built around the firm's actual practices.
Level 1: Ad hoc knowledge gathering
Institutional knowledge lives in memories and scattered folders. Lawyers and business professionals rely on DMS keyword searches, their own recollection, and whoever happens to be down the hall. Getting answers means tracking down the right partner, hoping they remember the deal, and reconstructing information from whatever they recall and whatever the DMS search tool happens to surface.
A Level 1 data maturity bears significant imputed and actual costs. When the same question arises in a different practice group or department, the cycle of time-consuming information retrieval repeats from the beginning. Partners spend time on document searches that should be spent on judgment. Business development teams prepare pitches with anecdotes rather than statistics. The quality of client service delivery and the generation of new business is impeded not by a lack of knowledge, but by a lack of availability.
Level 2: Manual codification
The firm recognizes the problem and starts capturing deal data in spreadsheets or internal databases. The firm is intentional about a data strategy, but is constrained by tedious processes and the friction of change management.
Manually populating the knowledge system competes with billable work for the same associate hours and is quickly deprioritized. Because the entries are produced by associates with varying perspectives and levels of experience, the data accumulates inconsistencies the moment it starts accumulating volume. And because the structured data lives separately from the underlying documents, confirming even minor details sends the reader back to the DMS, breaking their workflow.
In many Level 2 firms, knowledge systems tend to become siloed to specific use cases and are unknown to most associates and partners. Updates often happen quarterly, ahead of league table submissions or major pitches. The system does not capture evolving market trends on a cadence sufficient for client-facing guidance.
Level 3: General-purpose AI
The firm deploys a general-purpose AI tool, hoping it can finally turn the firm's deal history into something searchable. In practice, the tool helps a specific lawyer with a specific deal in front of them.
An associate working on a credit agreement remembers two analogous matters, finds them in the DMS, uploads them to a tabular review interface, and drafts a prompt asking the tool to compare a covenant package across the three. If the output quality is adequate, it might be useful to the attorney at that moment, but the next time a similar question arises, the next attorney will need to perform a similar workflow. Each time a user performs LLM-assisted data extraction, the firm - or the client, depending on billing practices - pays for tokens (either directly to the LLM provider, or indirectly to token resellers like general-purpose legal AI tools).
There is a deeper issue in addition to incomplete data. Most general-purpose legal AI tools are built on retrieval-augmented generation (RAG), which is designed to surface and summarize, not to reason across the interdependent provisions of a complex agreement. Legal documents with an intricate system of defined terms, cross references, and conditional logic are particularly vulnerable to the limits of standard retrieval methods. Sophisticated transactional work by nature requires tools that go beyond the standard limitations of retrieval and reasoning.
Many firms are experiencing Level 3 today as they experiment with general-purpose AI tools. Users burn tokens on redundant searches against incomplete subsets of the firm's deal history. Taxonomies and self-prompted knowledge bases proliferate at the individual, rather than firm, level. A Level 3 strategy sets firms on a perilous course where the harder they try to clean up their data with generic AI, the messier and more siloed it gets.
Level 4: Firm-wide deal intelligence
Deal intelligence is the firm's deal history converted into structured, citation-backed data that any user or system at the firm can access, with ethical walls enforced. It is not a search interface bolted onto a document repository. Nor is it a series of rows and columns prompted by a user in a workspace. A persistent deal data layer is an institutional asset that captures how provisions were negotiated, how risk was allocated, and how structures evolved across the firm's full transactional footprint.
Taxonomies are designed at the firm level and reflect each practice's unique perspective on deal structures, terms, and industry dynamics. New matters feed the dataset in real time. Any user at the firm, any practice group, and any downstream tool can query the deal database, powering precedent search, client pitches, negotiation benchmarking, and market analysis from a consistent, foundational layer.
This is what compounding intelligence looks like in practice: every closed deal makes the next one sharper, and the firms that arrive here first gain a head start on strategic client advisory that competitors cannot quickly close.
You don't need to climb sequentially
A common misconception is that firms have to progress through each level of the data maturity framework in order. Manual spreadsheets first, then horizontal AI, then deal intelligence. That path is slow, expensive, and unnecessary. Wherever a firm stands today, Level 4 is directly achievable with purpose-built products like Centari.
We often see firms taking bite-sized efforts toward a data strategy — a tracking spreadsheet here, a contract review tool there — only to spend years maintaining systems that were never designed to scale. Scattered efforts lead to lost time and a scramble to catch up with peers building a Level 4 strategic data layer.
Lead with your firm's strategic advantage
Each firm’s data strategy should reflect what already sets them apart in the market for legal services. Fundamentally, what is the firm’s competitive advantage? Which practice areas and deal types are they known for? Which structures does the firm see more of, or negotiate more tactically, than anyone else? The answers to these questions define what type of data the firm needs to capture, how it needs to be structured, and where it can deliver an outsized impact for clients.
Unlocking the firm’s deal intelligence at scale requires both the right technology and the optimal pairing of technologists, attorneys, and business experts. Centari's patent-pending Deal Reasoning Engine processes complex agreements the way a transactional lawyer would — tracing defined terms, mapping conditional logic, and reasoning across related documents to produce structured, citation-backed data. Our Applied Legal Research team, made up of former practitioners from firms like Kirkland & Ellis, McCarthy Tétrault, and Dechert, works alongside each firm to calibrate the platform to the firm's deal types and data needs.
Your data strategy shapes your future
Firms that build the data foundation now will own what competitors can't replicate: a proprietary intelligence layer, shaped by their own deal history, that puts collective experience at the point of decision.
Every firm has an AI strategy. The firms that will define the next decade of transactional practice have a deliberate data strategy underneath it.


