No lawyer reads a 300-page credit agreement from page one to page 300. A senior associate reviewing opposing counsel's draft on a tight deadline goes straight to the financial covenants, then to the defined terms to check how "Consolidated EBITDA" is calculated. That definition has five subclauses and two carve-outs that live elsewhere in the agreement, so the associate keeps moving: definition to covenant, covenant to exception, exception to schedule, working the document one issue at a time.
The associate reads this way because the document is built this way. The text is the interface. The system is what the lawyer is actually reading.
That distinction is the dividing line in legal AI today. It explains why tools that perform impressively on simple contracts stumble on complex transactions, why the most common engineering fixes fail to close the gap, and what it takes to produce deal data a firm can actually rely on.
Legal documents encode logic, not just language
A contract is a system of interlocking parts. Its definitions, rules, and conditions all depend on one another, because the drafters' job is to express the full logic of a transaction with as little ambiguity as possible. Each section exists in relation to other sections, and changing one element can shift the meaning of dozens of provisions.
Most of that logic lives in three structures:
Defined terms are a form of legend for the entire document. Terms like "Consolidated Total Debt," "Eligible Receivables," and "Material Adverse Effect" appear hundreds of times, and their scope informs the meaning of every provision that references them. In a leveraged credit facility, the definition of Consolidated EBITDA can run several pages, and the leverage covenant that determines whether the borrower is in compliance depends on that definition entirely. If you get the definition wrong, every compliance calculation built on it is wrong too.
Cross-references create dependencies between provisions, even when those provisions are separated by a hundred pages. A covenant on page 47 may be subject to an exception on page 112, which references a basket defined on page 10. The textual distance is irrelevant to the logical relationship: the three provisions form a single unit of meaning. Read the covenant without the exception, and you have misread the covenant.
Conditional logic determines whether a provision applies at all. A financial maintenance covenant might spring into effect only when the revolver is drawn beyond 35%. Whether the borrower is bound depends on a fact about the world plus a correct reading of the threshold and any step-downs negotiated elsewhere in the agreement. Miss a step-down, and you can incorrectly conclude a borrower is in compliance when it is actually in breach, or vice versa.
An experienced attorney navigates all three at once, jumping from a covenant to the definitions it relies on, and from the definitions to their exceptions, in whatever order the question at hand requires.
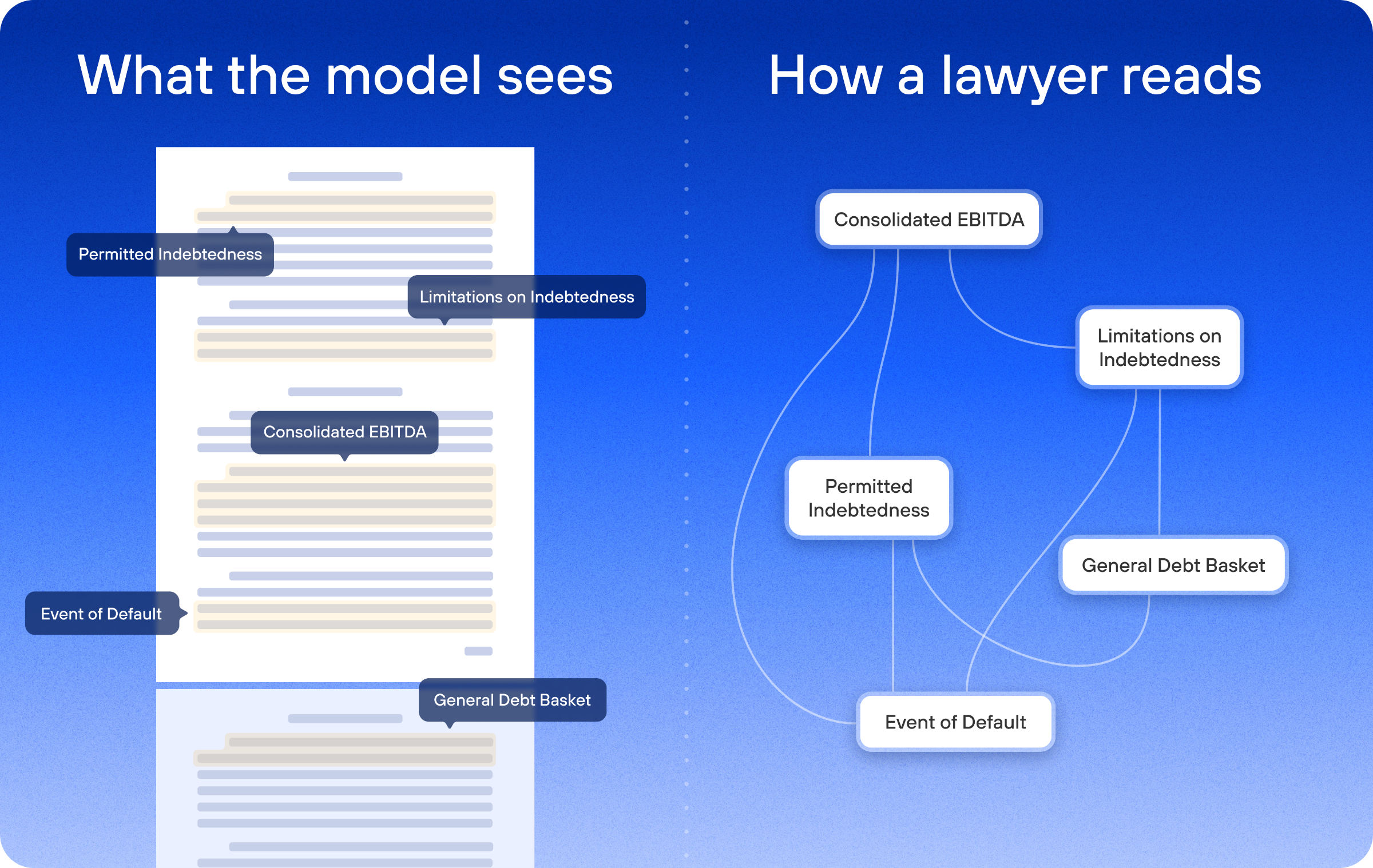
Where flat-text processing breaks down
A large language model reads a contract as flat text: one continuous sequence of words, processed in order, with no representation of the structure underneath. That approach works for many tasks. It breaks on complex agreements, because the model holds no map of defined-term chains, cross-reference dependencies, or the conditions that switch provisions on and off.
When an attorney jumps from a covenant to the definition it depends on, then to the amendment that limits its scope, they are following the document's logic. To a model reading flat text, those are three disconnected passages that happen to share vocabulary.
Why the standard fixes fall short
Whenever these limits are raised, there are three common technical responses: fine-tune the model, add retrieval, or use a bigger context window. Each helps at the margin. None addresses the structure.
Fine-tuning improves a model's command of legal vocabulary and drafting convention. Structural reasoning over a novel agreement is a different skill, and every negotiated deal is, by definition, novel.
Retrieval-augmented generation (RAG) improves recall, then discards the relationships. It retrieves the covenant and the definition as independent chunks, without capturing that the definition sets the covenant's scope, or that both are subject to an exception the system also retrieved but cannot connect. The system finds the right passages and loses what connects them. In a contract, the connections are the meaning.
Larger context windows guarantee the model has seen everything, but they do nothing to help it connect anything. If you feed in all 300 pages, the provisions that matter compete for the model's attention with boilerplate notice and governing-law clauses. Long-context research shows the pattern consistently: models have become good at retrieving isolated facts from long documents, and accuracy still drops when the task requires linking information spread across them. The limit was never how much of the document the model can see. It is whether the model understands how the pieces fit together.
These are general-purpose techniques applied to a specialized problem, and they fall short for the same reason: they operate on the text, while the meaning lives in the system.
From reading text to reasoning over the system
If a legal document is a system, reliable analysis requires building a representation of that system.
That is the design principle behind Centari's Deal Reasoning Engine. It maps the document's architecture before extracting meaning from it, identifying how defined terms, cross-references, and conditional dependencies relate across the full document set before answering any question about an individual provision. It follows the document's own logic: resolving definitions, tracing cross-references, evaluating thresholds in sequence. And it reasons across the entire deal, because amendments, side letters, and schedules change the meaning of provisions they never mention.
The result is structured deal data a practitioner can act on, because every answer is grounded in the document's actual logic and backed by citations to the provisions it came from. A model reading flat text surfaces passages for a human to interpret. The Deal Reasoning Engine surfaces answers that have already done the interpretive work: definitions resolved, references traced, conditions evaluated.
The question to ask before you invest
Firms are making AI investment decisions at scale right now, and the question underneath most of them is rarely asked directly: does this tool read the language, or does it read the logic?
The answer matters because in transactional practice, data feeds advice. If the data is wrong, the advice built on it is wrong, and a database of unreliable extractions becomes a liability that compounds with every deal added to it. When the data is right, the same compounding runs in the firm's favor: the 500th deal in the database makes the firm meaningfully smarter than the first.
The firms building a durable advantage in the AI era are the ones investing in their deal intelligence layer, and asking their technology providers precisely what their tools see when they read a deal.